

Generative AI: Who Is All This For?
Generative AI: Who Is All This For?
A lot has happened in generative AI so far. I dive into all of it, and ask who it's all for.


Last summer, I wrote a piece entitled “Is The Future of AI All In The Hands of Incumbents” where I questioned whether the current dominant players in technology stood to benefit the most from the ongoing AI revolution. Whenever there has been a paradigm shift in technology, new innovators often emerge to bring the new ideas to market. After all, Henry Ford was not the largest stablehand in America prior to launching Ford.

When I wrote the piece, Microsoft, Amazon, Meta and Google were already strongly positioning themselves for an AI dominated future and it seemed like we wouldn’t get new players to disrupt this status quo that overlords the internet. Let’s address where we stand today.
The reason you’re reading this piece probably has a bit to do with the feeling of awe you experienced when you used OpenAI’s ChatGPT for the first time. That watershed moment for AI had us all very excited, and also unsettled. What was this sentient computing future going to hold? Who would be in charge of it? Will I benefit? If I don't, who will?
While we were ooing and aahing, developments in AI continued at a rapid pace. GPT-4, OpenAI’s newest model, released in March of 2023, just 4 months after the world met its predecessor. Funding for new AI companies exploded and established players dedicated billions in order to turn AI-enabled ideas into future revenue streams. Press releases about strategic partnerships frequently dominated our news cycles and AI CEOs became internet celebrities. I’ll make sense of all the noise.
The Hyperscalers & Their Underlings
Hyperscalers are large cloud service providers, that can provide services such as computing and storage at enterprise scale. They are Microsoft Azure, Amazon Web Services and Google Cloud Partners.
These large enterprises have grabbed headlines during the AI revolution by investing heavily into AI startups such as OpenAI, Anthropic and Mistral. These are, crucially, all startups that are building their own large language models (LLMs). LLMs require immense amounts of capital and compute to pre-train and fine tune, and as I discussed last summer, regular startups wouldn’t be able to afford this. This is where the hyperscalers come in.
“A large language model (LLM) is a language model notable for its ability to achieve general-purpose language generation and understanding. LLMs acquire these abilities by learning statistical relationships from text documents during a computationally intensive self-supervised and semi-supervised training process” - Wikipedia

Microsoft (And OpenAI)
Microsoft and OpenAI’s AI stories are inextricably tied, much to the satisfaction of MSFT 0.00%↑ shareholders. However, it took a while for the computing giant to get here. A decade ago, the company was treading murky waters. They had just lost in mobile to Apple and Google and their shift to a subscription model for their office suite products had hurt revenues. Current CEO Satya Nadella took over from co-founder Steve Ballmer in 2014 and has since spearheaded the company to becoming the most valuable enterprise on earth, at an eye watering $3Tn valuation.
Most of this value was added once investors took notice of Microsoft’s aggressive stance towards AI. In January 2023, Nadella announced an extension of the company’s long term “partnership” with OpenAI, which has been in place since the former non-profit decided to become a closed for-profit company in 2019. This news was announced alongside a $10Bn investment and a confirmation that OpenAI’s tools would soon become a part of Microsoft products such as Office Suite, Teams and Github.
I say partnership in quotes because this relationship is far from ordinary. What has become clear over time is that this $10Bn comes in the form of cloud credits, not hard cash. You see, Microsoft has a cloud computing service, Azure. Ordinarily, OpenAI would need to pay a cloud provider for all the intensive compute needed to train and run their products. For a nascent company, this would be very expensive. In steps Microsoft, offering billions of dollars worth of cloud credits in exchange for what is now 49% of the company.

“Only a fraction of Microsoft’s $10 billion investment in OpenAI has been wired to the startup, while a significant portion of the funding, divided into tranches, is in the form of cloud compute purchases instead of cash, according to people familiar with their agreement.” - Semafor
In simple terms, this is their own money (capital expenditure) coming back to them in the form of cloud revenues. A gaming of the system, so to speak.
All this “investment” from Microsoft has paid off, not only by propping up their balance sheet by turning venture investments into cloud revenues, but also by instilling investor confidence in the company’s strong positioning for an AI future. So much so that they’re now the most valuable company on earth at time of writing.

Google (Gemini And Mistral)
Google GOOG 0.00%↑ find themselves at an interesting crossroads. In 2017, a group of brilliant scientists & researchers from their Deep Mind AI division wrote the now-acclaimed “Attention is All You Need” research paper which introduced the transformer. This paper opened the door to the understanding and creation of LLMs as we know them today. GPT literally stands for “Generative Pre-Trained Transformer”.
“Transformers are a type of neural network architecture that transforms or changes an input sequence into an output sequence. They do this by learning context and tracking relationships between sequence components. For example, consider this input sequence: "What is the color of the sky?" The transformer model uses an internal mathematical representation that identifies the relevancy and relationship between the words color, sky, and blue. It uses that knowledge to generate the output: "The sky is blue." - Amazon Web Services
Unfortunately, Google themselves were unable to capitalize on their own discovery and found themselves flat-footed when OpenAI’s GPT-3.5 launched in 2022. Even more so, because the chat box nature of GPT-3.5 gave the world a glimpse into a future where Google Search’s 10 blue links are not the default source of information on the internet.
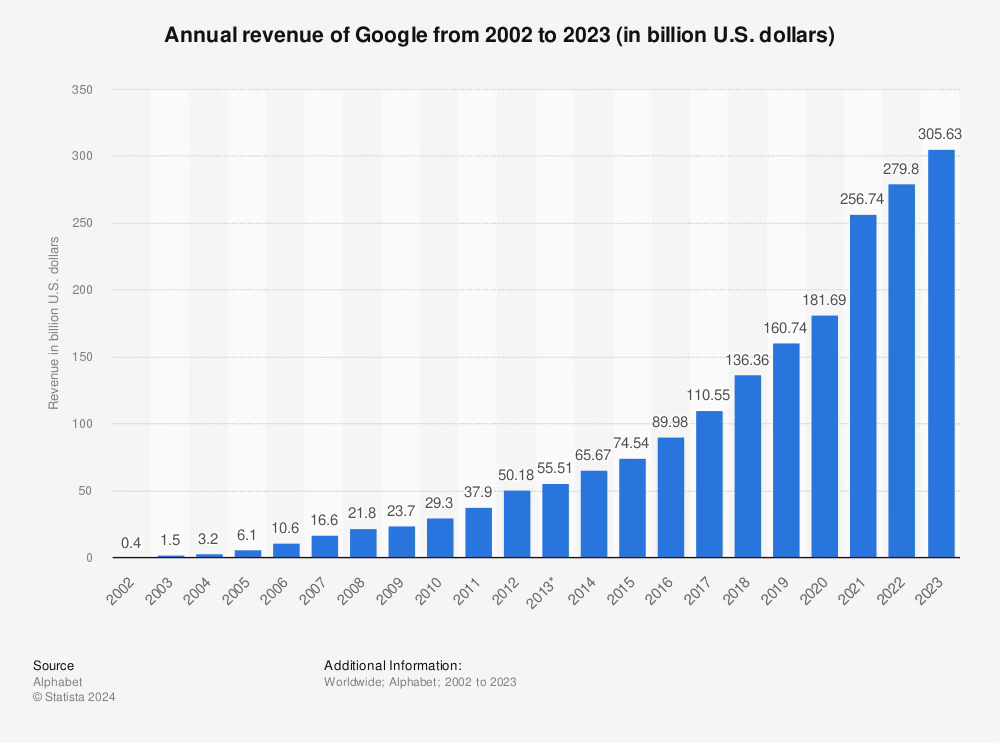
Despite a dominance in search revenue, Google’s search query volume growth has been stagnating. The compounded annual growth rate of search engine result pages sits at a measly 4%. Since peaking in the early 2010s, there simply are not enough people in the world to keep Googling things who are not Googling things already. This was the case even before generative AI search tools such as ChatGPT and Perplexity became available.

Additionally, Google’s focus on maximizing digital advertising revenue has undermined the Google search experience over the last few years. The quality of a Google search has reduced as search engine optimized (SEO) spam dominates the top links.

This diminished search experience was a major reason why Chat-GPT rose to prominence as quickly as it did, initially becoming the fastest website in history to reach 100 million users. Answers without the ads were very compelling to consumers, and still are, with new startup Perplexity AI quickly rising to prominence this market category.
However, it costs a lot more money to perform an LLM search than it costs Google to provide 10 blue links. Industry analysts have estimated that it costs around 10x more for a LLM-based query i.e asking Chat-GPT a question compared to an informational one that you would perform on Google or Bing. Furthermore, the fact that informational queries can offer ads makes them orders of magnitude more profitable. This raises questions regarding the sustainability of the LLM search business model. How long can ChatGPT and Perplexity even keep this up? Will they have to inevitably add ads?

Despite LLM-based search being a direct existential threat to Google’s core business model, they have thrown their hat in the ring. Gemini 1.5 is their current proprietary LLM-based search product, which also has image generating capabilities. This is the latest in a series of LLM-enabled search products that they have released, preceded by Google Bard.
It will be interesting to see how Google manages this balancing act; they clearly need Google Search to continue being incredibly profitable, all the while fighting the emerging competition in the form arguably better search experiences from competitors.
Mistral AI is a French based AI startup that builds open-source large language models. In late 2023, it was announced that Google Cloud would partner with them on cloud infrastructure in order to build and scale up their models. More chips on the table for the search giant as it tries to navigate its uncertain future.
Amazon (And Anthropic)
Amazon AMZN 0.00%↑ were not to be left behind in the AI arms race. Their cloud providing service, AWS, has grown to become the dominant player in cloud infrastructure services over the last 15 years. This very blog is hosted on AWS.
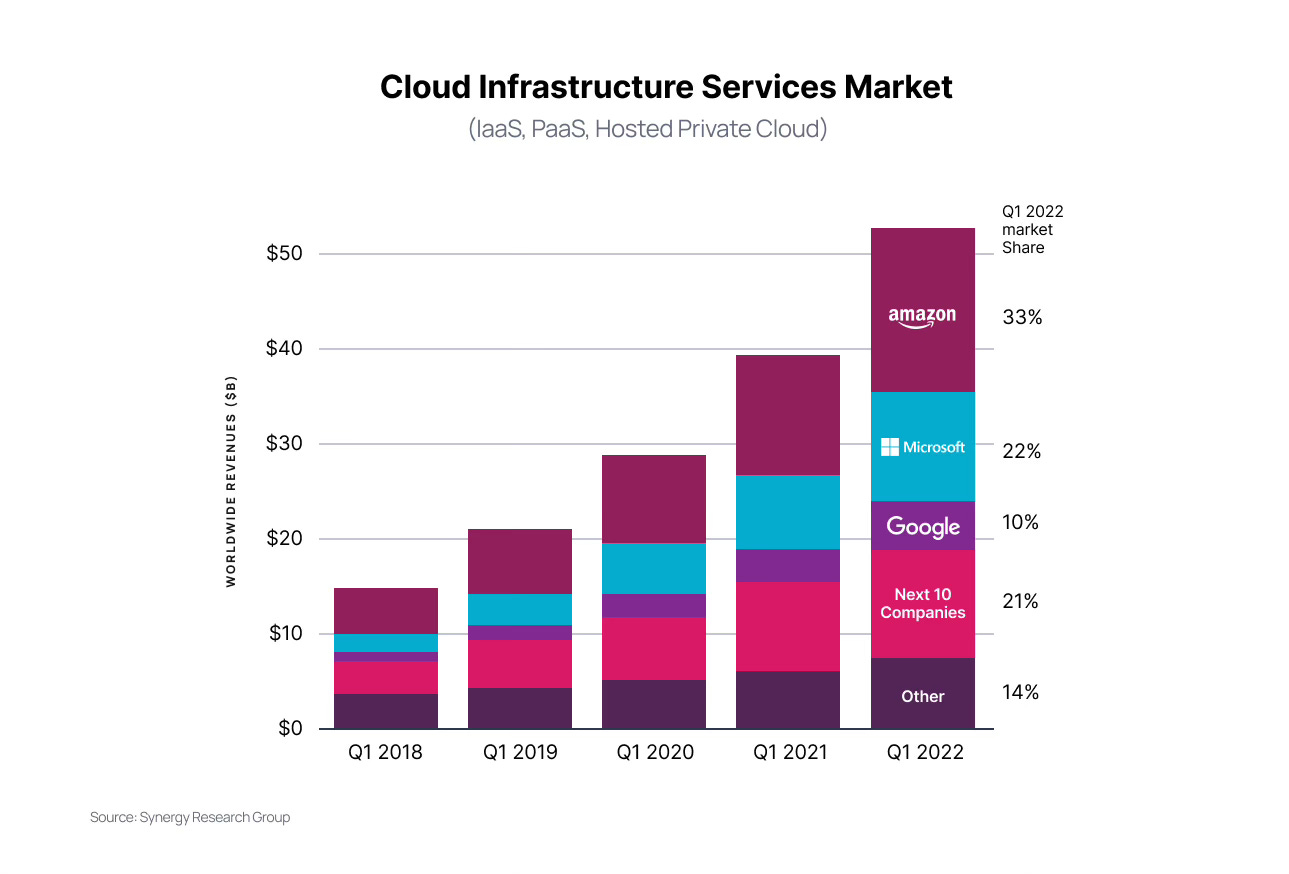
Amazon entered into a $4Bn strategic partnership with Anthropic AI in 2023 in order to leverage this compute to help the startup with their extensive training requirements for their large language model, Claude. An investment that undoubtedly came with a large ownership stake. This is a rerunning of the Microsoft - OpenAI and Google - Mistral playbooks from earlier.
By investing in infra-consuming startups such as Open AI, “hyperscalers” such as Microsoft, Google and Amazon can ensure the optimal utilization of their cloud services, reducing the risk around their sizeable capital deployment in other areas.
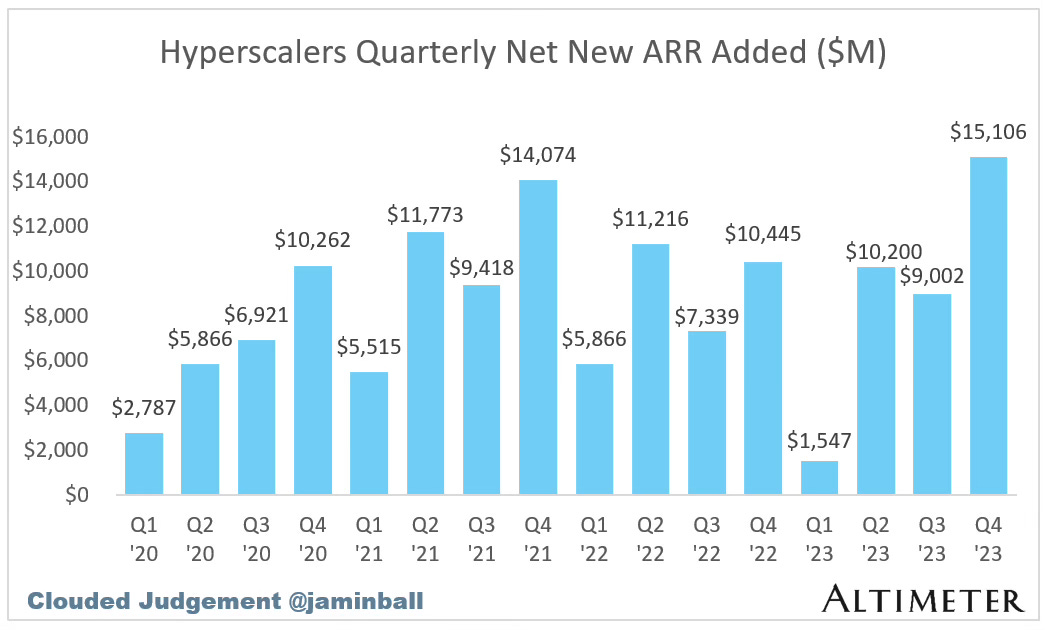
This strategy has so far paid off, with the 3 hyperscalers showing record aggregate new annual recurring revenue (ARR) added in Q4 2023 - $15Bn across the 3 of them. An absurd number considering how mature these companies are. Most of this revenue undoubtedly coming from the AI training workloads from the companies they “invested” in.
The Training Set Wars
In order to train an LLM, one needs a training set. Think of it this way, the reason Chat-GPT replies the way it does is that it has been trained by billions of human conversations and thus it is able to respond accordingly, in a human-like manner, for almost every query. The capability of an LLM is directly dependent on its training set.
“The training set is the material through which the computer learns how to process information. Machine learning uses algorithms – it mimics the abilities of the human brain to take in diverse inputs and weigh them, in order to produce activations in the brain, in the individual neurons.” - Techopedia
Some training sets are more valuable than others. A training set of every Facebook post in history would be a lot more valuable than a training set of me and my 3 friends iMessage group chat, where we routinely remind each other when its time for pick up soccer. Despite this, both can be useful training sets.
Experts believe that businesses and social networking sites have very valuable training sets. Imagine if I owned a dentistry and I had a repository of every single customer interaction I have ever had. I could potentially train a small language model capable in answering patient questions, booking appointments and facilitating payments all on its own. Similarly, imagine training an LLM with the Twitter (X) training set and giving it knowledge of every tweet and thread that has ever been posted on that site. This would be very powerful. As a result, companies have begun a hunt for valuable training sets and are willing to pay top dollar.
Recently, the New York Times sued OpenAI for allegedly infringing copyright laws by training their GPT-3.5 model on their articles. This is a landmark case whose result may shape how LLM’s are trained in future. The effects are already beginning to show though, as Reddit recently announced a $60m licensing of their library of posts to Google for model training.
The years to follow may result in regular civilians having their posts used as training data for a revenue-producing LLM that they do not benefit from. All your Facebook posts, Tweets and Tiktok’s may be training an AI model as we speak! or already have! This very blog may be used as training data, according to Substack.

Would you consent to have an AI get trained on your social media data?
AI-Generated Photo & Video
One of the highlights of the last 7 months has been the emergence of hyper-realistic AI-generated photo and video content. OpenAI’s DALL.E & Sora, Microsoft’s Bing Image Generator, Midjourney and Google’s Gemini have all caught the attention of internet users the world over for both good and bad.
The speed of development has been alarming, with critics posturing that the rate of change is too rapid to allow for proper regulation of what kind of content can be generated and where it can be used. My fellow writer
has phenomenal commentary on the ethical ramifications of these technologies, and I would recommend giving her work a look.
Recently, generative AI - fueled controversy reached fever pitch when a very famous pop star had sexual AI-generated images in her likeness go viral online. This sparked an already ongoing debate about how companies and governments can better regulate exactly what these technologies are able to generate.
Last week, OpenAI unveiled Sora, their frontier technical model that generates ultra-realistic and imaginative video scenes from text instructions. The demos were incredible, but launch has been paused until “several safety steps are taken ahead of making Sora publicly available”.
The creative industries will be no doubt holding their breath. Actors, designers, writers, illustrators, visual effects artists and many others may indeed be facing existential threats to their careers as content generation capabilities continue to develop. Governments, unions and governing bodies are already lobbying against these tools hitting the mass market.
My belief is that in a world where anyone can create anything, then taste is the only moat. The best quality stories, movies and television shows will continue to prevail.
Who Is All This For?
That was my primer on where we stand in the world of generative artificial intelligence today, and these are my thoughts.
I worry about the current tech overlords maintaining their vice grip on the world as we shift into this new paradigm. I worry that these tools, which are being created on the premise of making everybody's lives easier, may instead replace everybody’s labour, relegating the masses to something even lower than the working class. I worry about whether some of this is progress for progress’ sake.
We still need emergent players to take market share from the current incumbents. The current state of social media and its adverse effects on teens and young adults, the demise of Google Search and the rate at which cultural pillars within fields such as journalism and media are disappearing is enough to show us that the current method, with the current overlords, is not working. We need change.
Hopefully AI brings that change, but I am skeptical.
Great read! Generative AI's scope is immense. Thanks for shedding light on this topic. https://colaninfotech.com/blog/google-generative-ai-search-vs-chatgpt/
Insightful analysis. I think this industry is headed towards consolidation. There are notable barriers to entry, whether in the development of LLMs or access to capital. Microsoft does appear to have an edge here. However, generally, big tech (Google, Amazon, etc. ) can buy off competition, and that competition, especially from startups, does have the incentive to be bought by these.
Who is all this for? I think it's for big tech. They'll build it, then they start rationing it to extract the most out of it. Time will tell, and its' never wise to rule out possibilities, esp in the tech industry. Still, I believe these big companies have their hands on the pulse of all developments in AI, and they'll use their monopoly to ensure independent players cannot pose a threat in the long run.